Test AI agents, voice agents, and chatbots against real attacks
A single misconfigured agent can leak sensitive data, misuse internal tools, or make commitments your business never approved. That applies to voice agents, chatbots, and agents with tool access. We uncover where your systems are already vulnerable before it becomes expensive.
What production AI agents put at risk
AI agents are built on LLMs that work probabilistically: they sound confident, but they are not deterministic. The same request can lead to very different answers, hallucinations, or unexpected actions depending on context.
That is why production voice and chat setups need a second line of defense: technical guardrails, automated testing, and monitoring. With the EU AI Act, the pressure grows to visibly monitor AI systems and continuously reduce risk.
When the agent talks or writes directly to customers
A voice agent or chatbot answers questions about contracts or invoices and promises goodwill, discounts, or deferrals that are not covered by your policies. Individual wrong commitments quickly scale with every additional contact.
When the agent is wired into internal systems
Your agent can create tickets, modify customer data, prepare emails, or trigger payments. A jailbreak or clever prompt variation can be enough to trigger unintended actions or expose sensitive information.
When monitoring and governance are missing
Without structured tests and reporting, you have no clear view of what your agent actually says today. Internal risk teams and regulators in the context of the EU AI Act lack the basis to assess risk and quality in a transparent way.
How exposed AI voice systems already are
Behind every polished demo there is a messy reality: automated attacks, misconfigurations, and incidents that never make it into a public report. The question is less if someone tries to break your agents and more whether you notice it.
estimated automated probing attempts per day across publicly exposed AI interfaces (email, chat, voice, web)
of companies report at least one security or compliance incident linked to AI or automation in the last 12 months
of incidents are actually reported. Many are discovered late or not at all. Your agents might already have been abused without anyone noticing.
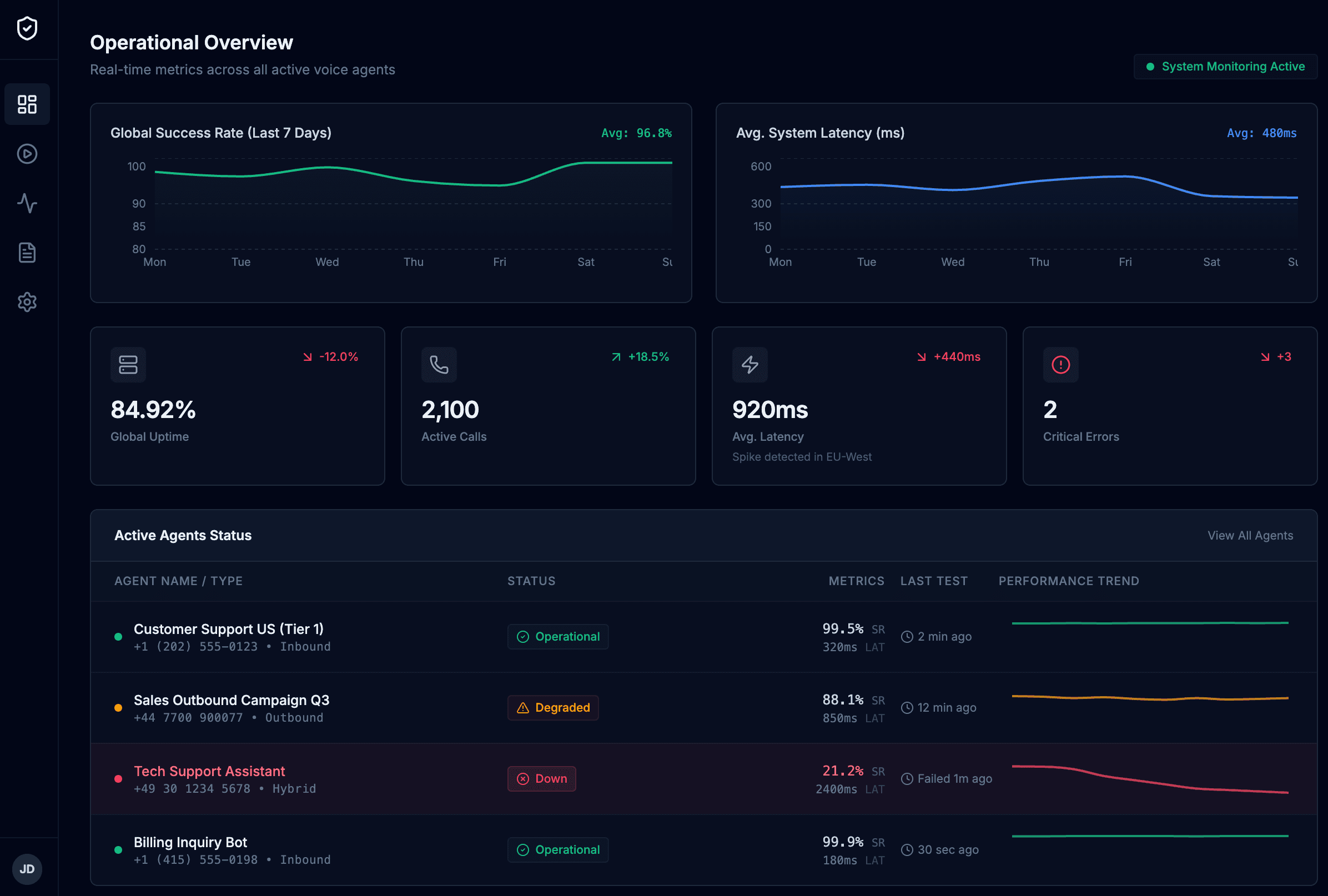
Internal platform for monitoring and on-demand tests
The platform makes testing and monitoring your voice agents, chatbots, and tool-using agents simple and repeatable.
- Ad-hoc test runs
- Continuous regression tests
- Uptime monitoring & alerts
- One-click reports
- Multi-agent overview
Attacks we simulate for you
We combine known weaknesses from recent research papers, public jailbreak databases, and our own attack patterns from real projects.
Prompt injection & jailbreaks
We test systematic attempts to override system prompts, shift policy boundaries, and gradually erode security instructions, including multi-step conversation chains.
Data leakage & compliance violations
Can a user indirectly query internal information, sensitive customer data, or internal tools? We identify where your current answers already reveal more than they should.
Tool and workflow abuse
As soon as your voice agent can perform external actions (e.g. sending emails, creating tickets, preparing payments), we specifically test abuse scenarios and unwanted side effects.
Security you can measure, not just hope for
attack patterns tested (including known jailbreak and prompt-injection techniques)
average success rate of critical attacks during first runs in new setups
continuous regression tests possible, every change can be checked automatically
In-depth whitepaper on AI agent security
In our whitepaper we cover common weaknesses in voice agents, chatbots, and tool-using agents, concrete attack paths, and best practices for guardrails, monitoring, and continuous testing.
Test your AI agents under real-world conditions
We combine hands-on automation experience with a deep understanding of modern LLM security. Talk to us about your use case or start directly with an initial test run.