Testen Sie AI Agents, Voice Agents und Chatbots gegen reale Angriffe
Ein einzelner fehlkonfigurierter Agent kann vertrauliche Daten preisgeben, interne Tools missbrauchen oder falsche Zusagen machen. Das gilt für Voice Agents, Chatbots und Agents mit Tool-Zugriff. Wir zeigen, wo Ihre Systeme heute schon angreifbar sind, bevor es teuer wird.
Welche Risiken produktive AI Agents erzeugen
AI Agents basieren auf LLMs, die probabilistisch arbeiten: Sie klingen sicher, sind aber nicht deterministisch. Ein und dieselbe Anfrage kann je nach Kontext zu völlig unterschiedlichen Antworten, Halluzinationen oder unerwarteten Aktionen führen.
Deshalb brauchen produktive Voice- und Chat-Setups eine zweite Verteidigungslinie: technische Guardrails, automatisierte Tests und Monitoring. Spätestens mit dem EU AI Act steigt der Druck, den Betrieb von AI Agents nachweisbar zu überwachen und Risiken kontinuierlich zu reduzieren.
Wenn der Agent direkt mit Kunden spricht oder schreibt
Ein Voice Agent oder Chatbot beantwortet Rückfragen zu Verträgen oder Rechnungen und verspricht Kulanz, Rabatte oder Stundungen, die in Ihren Policies gar nicht vorgesehen sind. Einzelne falsche Zusagen skalieren mit jedem weiteren Kontakt.
Wenn der Agent an interne Systeme angebunden ist
Ihr Agent kann Tickets erstellen, Stammdaten ändern, E-Mails vorbereiten oder Zahlungen anstoßen. Ein Jailbreak oder eine clevere Prompt-Variation reicht, um ungewollte Aktionen auszulösen oder sensible Daten offenzulegen.
Wenn Monitoring und Governance fehlen
Ohne strukturierte Tests und Reporting bleibt unklar, welche Antworten Ihr Agent heute schon gibt. Für interne Risk-Teams und im Kontext des EU AI Act fehlt die Grundlage, um Risiken und Qualität nachvollziehbar zu bewerten.
Wie stark AI Voice-Systeme heute schon angegriffen werden
Hinter jedem sauberen Demo-Call steckt eine unübersichtliche Realität: automatisierte Angriffe, Fehlkonfigurationen und Vorfälle, die nie in einem Bericht landen. Die Frage ist weniger, ob jemand Ihre Agents angreift. Entscheidend ist, ob Sie es merken.
geschätzte automatisierte Probing-Versuche pro Tag über öffentlich erreichbare AI-Interfaces (E-Mail, Chat, Voice, Web)
der Unternehmen berichten von mindestens einem Sicherheits- oder Compliance-Vorfall im Zusammenhang mit AI oder Automatisierung in den letzten 12 Monaten
der Vorfälle werden tatsächlich gemeldet. Viele werden erst spät oder gar nicht entdeckt. Möglicherweise wurden Ihre Agents bereits missbraucht, ohne dass es jemand bemerkt hat.
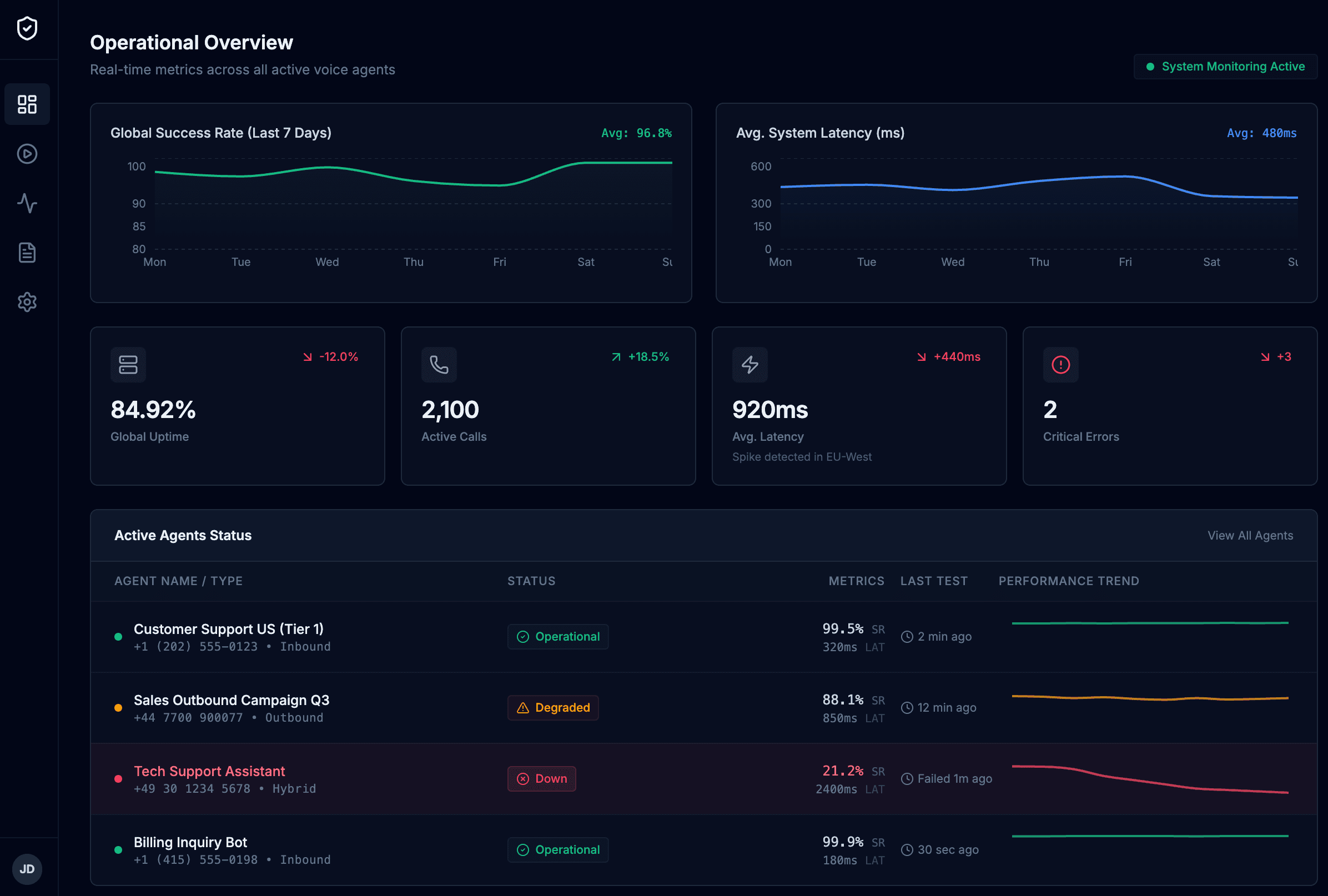
Interne Plattform für Monitoring und Ad-hoc-Tests
Die Plattform macht Tests und Monitoring Ihrer Voice Agents, Chatbots und tool-nutzenden Agents einfach und wiederholbar.
- Ad-hoc-Tests
- Kontinuierliche Regressionstests
- Uptime-Monitoring & Alerts
- Reports auf Knopfdruck
- Multi-Agent-Übersicht
Welche Angriffe wir für Sie nachstellen
Wir kombinieren bekannte Schwachstellen aus aktuellen Research-Papers, öffentlichen Jailbreak-Datenbanken und eigene Angriffsmuster aus realen Projekten.
Prompt Injection & Jailbreaks
Wir testen systematische Versuche, System-Prompts zu überschreiben, Policy-Grenzen zu verschieben und Sicherheitsinstruktionen Schritt für Schritt auszuhöhlen, inklusive mehrstufiger Konversationsketten.
Datenabfluss & Compliance-Verstöße
Kann ein Nutzer interne Informationen, vertraulige Kundendaten oder interne Tools über Umwege abfragen? Wir prüfen, welche Antworten heute schon mehr verraten, als sie sollten.
Tool- und Workflow-Missbrauch
Sobald Ihr Voice Agent externe Aktionen ausführen darf (z. B. E-Mails versenden, Tickets anlegen, Zahlungen vorbereiten), testen wir gezielt Missbrauchsszenarien und ungewollte Nebenwirkungen.
Messbare Sicherheit statt Bauchgefühl
getestete Angriffsmuster (inkl. bekannter Jailbreak- und Prompt-Injection-Techniken)
durchschnittliche Erfolgsquote kritischer Angriffe bei ersten Tests in neuen Setups
kontinuierliche Regressionstests möglich. Jede neue Änderung wird automatisch geprüft
Vertiefendes Whitepaper zu AI Agent Security
In unserem Whitepaper beleuchten wir typische Schwachstellen von Voice Agents, Chatbots und tool-nutzenden Agents, konkrete Angriffspfade sowie Best Practices für Guardrails, Monitoring und kontinuierliches Testing.
Ihre AI Agents unter realen Bedingungen testen
Wir kombinieren praktische Automatisierungserfahrung mit tiefem Verständnis für moderne LLM-Sicherheit. Sprechen Sie mit uns über Ihren Anwendungsfall oder starten Sie direkt mit einem ersten Testlauf.